Die Entwicklung eines Systems zur Informationsgewinnung und Beantwortung von Fragen (RAG), das Informationen aus verschiedenen Quellen aufnimmt, ist mit zahlreichen technischen Hürden verbunden. In diesem Beitrag werden diese Herausforderungen anhand praktischer Erfahrungen diskutiert.
Zunächst erfasst das System Daten aus Confluence-Seiten, PDFs, Präsentationen, Excel-Tabellen und Code-Repositorys. Jede Quelle erfordert spezielle Adapter für die Analyse und Extraktion von Inhalten.
Text aus Confluence-Seiten stellt aufgrund seiner Einfachheit und leichten Erfassung nur minimale Herausforderungen dar.
Maßgeschneiderte Diagramme in Präsentationen stellen eine große Herausforderung für die Interpretation dar, da sie oft nicht standardisiert und auf bestimmte Kontexte zugeschnitten sind und daher ein fortgeschrittenes visuelles Verständnis erfordern. Diese Diagramme enthalten häufig auch unternehmensspezifische Abkürzungen und Informationen, was die Interpretation zusätzlich erschwert. Um sie vollständig zu verstehen, muss man in der Regel andere Teile des Dokuments heranziehen, wodurch Abhängigkeiten entstehen, die eine genaue und umfassende Interpretation noch schwieriger machen.
Um die in Dokumenten eingebetteten visuellen Informationen zu verarbeiten, wurden drei Hauptansätze evaluiert:
1. OCR-basierte Extraktion: Modelle zur optischen Zeichenerkennung (OCR) können sichtbaren Text aus Bildern extrahieren. Diese Methode ist zwar leicht und schnell, kann jedoch häufig die zugrunde liegende Struktur, Semantik und die in Diagrammen eingebetteten Beziehungen nicht erfassen. OCR fehlt das Bewusstsein für räumliche Hierarchien und Interpretationen auf Komponentenebene in benutzerdefinierten Illustrationen, sodass es für tiefere semantische Aufgaben nicht ausreicht.
2. Visuelle LLMs (VLMs): Visuelle Large Language Models versuchen, visuelle Inhalte zu verarbeiten und in detaillierte Textbeschreibungen umzuwandeln. Dies kann auf zwei Arten erfolgen:
3. Multimodale Einbettung: Bei dieser Methode wird das gesamte Bild ohne textuelle Übersetzung direkt in einen Vektorraum eingebettet. Dadurch bleibt zwar die visuelle Integrität erhalten, jedoch gibt es Probleme mit der Spezifität und der Genauigkeit der Suche. Eine einzelne Folie oder ein Diagramm enthält oft eine große Menge an Informationen – entsprechend mehreren Minuten Erklärung oder einer ganzen Textseite. Die Einbettung einer solchen Folie als einzelne Einheit erschwert es, später bestimmte Entitäten – wie den Namen einer Person oder die Bezeichnung einer Dienstleistung – zu extrahieren oder abzugleichen, insbesondere wenn diese nur visuell kodiert sind. Infolgedessen kann die Abrufphase die semantische Zuordnung von Benutzeranfragen zu den relevanten Bildfragmenten nicht gewährleisten.
Der effektivste Ansatz war die Verwendung von Visual LLMs zur Generierung einer strukturierten textuellen Darstellung des Bildinhalts. Diese Methode ermöglicht die Extraktion von Entitäten, Beziehungen und Layout-Semantik in einer Weise, die die Interpretierbarkeit bewahrt und die Abhängigkeit von einer brüchigen, nur auf Bildern basierenden Ähnlichkeitsabfrage vermeidet.
Die Aufteilung des Textes in überschaubare Einheiten stellte eine weitere technische Herausforderung dar. Die gewählte Strategie ist die rekursive Chunking-Methode, bei der Überschriften und Unterüberschriften verwendet werden, um die Kohärenz zu gewährleisten. Als optimale Chunk-Größe wurde eine Größe von etwa 1.000 Tokens mit einer Überlappung von 200 Tokens ermittelt. Jeder Chunk enthält Metadaten wie die URLs der Dokumentquellen und Kontextinformationen.
Um ein vollständig privates, lokal gehostetes System zu gewährleisten, verwenden Dokument-Einbettungen NOMIC-Modelle mit einer Vektorgröße von 768 Dimensionen, während Code-Einbettungen Jinja-Modelle ebenfalls mit einer Vektorgröße von 768 Dimensionen verwenden.
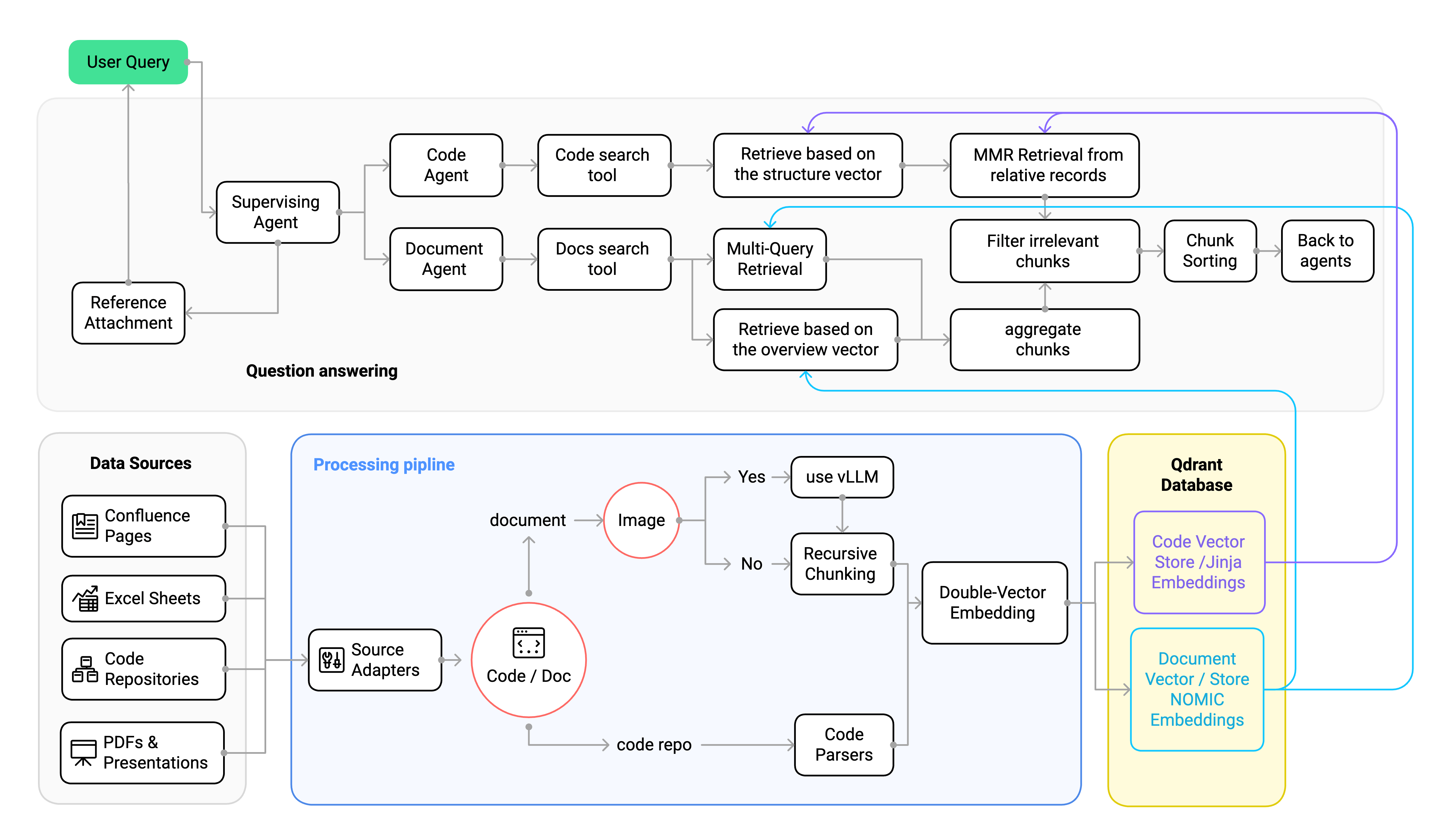
Das folgende Diagramm veranschaulicht die Gesamtarchitektur des RAG-Systems und zeigt, wie verschiedene Komponenten zusammenwirken, um Abfragen zu verarbeiten und Informationen abzurufen:
1```mermaid
2flowchart LR
3 subgraph subGraph0["Data Sources"]
4 O["Confluence Pages"]
5 P["P
6DFs & Presentations"]
7 Q["Excel Sheets"]
8 R["Code Repositories"]
9 end
10 subgraph subGraph1["Processing Pipeline"]
11 S["Source Adapters"]
12 U["Recursive Chunking"]
13 V["Double-Vector Embedding"]
14 n3["Code / Doc"]
15 n4["Code parsers"]
16 n5["Image"]
17 n6["use vLLM"]
18 end
19 subgraph subGraph2["Question Answering"]
20 K["Chunk Sorting"]
21 M["Reference Attachment"]
22 D["Document Agent"]
23 E["Code Agent"]
24 B["Supervising Agent"]
25 n1["Docs search tool"]
26 n2["Code search tool"]
27 I["Multi-Query Retrieval"]
28 J["MMR Retrieval from relative records"]
29 n7["Retrieve based on the structure vector"]
30 n8["Retrieve based on the overview vector"]
31 n9["Filtering irrelevant chunks"]
32 n10["aggregate chunks"]
33 n11["Back to agents"]
34 end
35 subgraph Databse["Qdrant Database"]
36 G["Document Vector Store<br>NOMIC Embeddings"]
37 H["Code Vector Store<br>Jinja Embeddings"]
38 end
39 A["User Query"] --> B
40 B --> D & E & M
41 D --> n1
42 E --> n2
43 O --> S
44 Q --> S
45 R --> S
46 S --> n3
47 U --> V
48 V --> G & H
49 n1 --> I & n8
50 M --> A
51 n2 --> n7
52 I --> n10
53 J --> n9
54 n3 -- code repo --> n4
55 n3 -- document --> n5
56 n4 --> V
57 P --> S
58 n5 -- Yes --> n6
59 n6 --> U
60 n5 -- No --> U
61 n7 --> J
62 n8 --> n10
63 n9 --> K
64 H --> J & n7
65 G --> n8 & I
66 n10 --> n9
67 K --> n11
68 n3@{ shape: decision}
69 n5@{ shape: diam}
70 style G stroke:#2962FF
71 style H stroke:#AA00FF
72 style A fill:#00C853
73 style subGraph1 fill:#BBDEFB
74 style Databse fill:#FFF9C4
75 linkStyle 29 stroke:#AA00FF,fill:none
76 linkStyle 30 stroke:#AA00FF,fill:none
77 linkStyle 31 stroke:#2962FF,fill:none
78 linkStyle 32 stroke:#2962FF,fill:none
Die Dokumentaufteilung wird vereinfacht, indem Text in das Markdown-Format konvertiert wird, wobei ein rekursiver Ansatz auf Basis von Markdown-Elementen verwendet wird, um die Kontextkohärenz zu gewährleisten. Umgekehrt stellt die Code-Chunking aufgrund struktureller Elemente wie Funktionen und Klassen, die möglicherweise aufgeteilt werden, eine besondere Herausforderung dar. Eine implementierte Lösung ist die Verwendung von Tree-Splittern, die die Codestruktur analysieren, um die Integrität der Chunks sicherzustellen. Dokumente und Code werden in separaten Datenbanken gespeichert, um Metadaten eindeutig zu verwalten. Diese Trennung ist unerlässlich, da für jede Modalität unterschiedliche Einbettungsmodelle verwendet werden – Dokumenteneinbettungen konzentrieren sich auf die Textsemantik, während Codeeinbettungen für die strukturelle und syntaktische Darstellung optimiert sind. Durch die Trennung bleibt der Abrufprozess sauber und zielgerichtet und eine Kontextverfälschung zwischen den Domänen wird verhindert. Außerdem wird der Abruf effizienter und skalierbarer, sodass das System individuelle Datenbanken pro Projekt oder Repository verwalten kann. Diese Architektur ermöglicht selektive Abfragen über bestimmte Repositorys oder Dokumentengruppen hinweg, ohne irrelevante Daten zu laden, was mit zunehmender Größe des Systems immer wichtiger wird.
Der Retrieval umfasst die Verarbeitung von Benutzeranfragen durch Agenten, die von einem übergeordneten Agenten koordiniert werden. Die Entscheidung für einen agentenbasierten Ansatz ergibt sich aus der Notwendigkeit, Komplexität zu bewältigen und Funktionen auf skalierbare Weise zu modularisieren. Anstatt einen einzelnen LLM mit allen Retrieval- und Syntheseaufgaben zu überlasten, werden die Aufgaben auf spezialisierte Agenten verteilt.
Konkret werden zwei Retrievalagenten verwendet: einer für die Bearbeitung von Dokumentanfragen und einer für codebezogene Anfragen. Jeder Agent ist für seinen Bereich optimiert – er nutzt unterschiedliche Einbettungsmodelle, fragt separate Vektorspeicher ab und interpretiert domänenspezifische Semantiken entsprechend. Diese Trennung verhindert eine gegenseitige Verfälschung der Ergebnisse, reduziert das Risiko von Halluzinationen und ermöglicht eine klarere Rückverfolgbarkeit der Ergebnisse. Darüber hinaus kann der Code-Agent auf spezialisierte LLMs zurückgreifen, die für Programmieraufgaben trainiert wurden – beispielsweise coderorientierte Modelle –, die ein viel tieferes Verständnis der Codesemantik, -syntax und -muster haben. Dies verbessert sowohl die Relevanz als auch die Qualität der Antworten auf codebezogene Fragen und macht das Gesamtsystem in Software-Engineering-Szenarien robuster und kontextgenauer.
Darüber hinaus ermöglicht diese Architektur eine einfache Erweiterbarkeit: Einzelne Projekte oder Codebasen können über einen eigenen Abrufagenten oder eine zugehörige Datenbank verfügen, die bei Bedarf dynamisch ausgewählt oder abgefragt werden können. Diese Modularität stellt sicher, dass das System auch bei wachsendem Umfang und zunehmender Komplexität der Wissensdatenbank wartbar und skalierbar bleibt.
Für die Code-Abfrage wird die maximale marginale Relevanz (MMR) verwendet, um vielfältige Ergebnisse zu gewährleisten. Der Dokumentabrufprozess nutzt einen Multi-Query-Ansatz, um die Relevanz zu verbessern.
Mit allen Komponenten – einschließlich modularer Adapter, Chunking und einer agentenbasierten Abrufarchitektur – ist das System nun in der Lage, eine Vielzahl von Fragen zu beantworten. Es ist jedoch ebenso wichtig, die Grenzen dessen zu erkennen, was zuverlässig beantwortet werden kann und was nicht. In den folgenden Abschnitten werden die Arten von Fragen untersucht, die das System bearbeiten kann, die Bedingungen, die erfüllt sein müssen, damit die Antworten korrekt sind, und die grundlegenden Herausforderungen, die trotz dieses strukturierten Designs bestehen bleiben.
Dokumentbezogene Fragen umfassen verschiedene Szenarien:
Code-bezogene Fragen decken ebenfalls eine Reihe von Komplexitäten ab:
Verbesserte Einbettungsstrategien führen doppelte Vektoreinbettungen ein, die Inhalte und kontextbezogene Metadaten kombinieren. Dies ist von entscheidender Bedeutung, da die alleinige Verwendung des Chunk-Inhalts häufig nicht ausreicht, um die für eine genaue Abfrage erforderliche Dokument- oder Codestruktur zu erhalten.
Bei Dokumenten wird der Kontext eines Chunks oft nicht nur durch den Absatz selbst definiert, sondern auch durch seine Position in einem größeren Abschnitt – wie einem Anwendungsfall, einer Dienstbeschreibung oder einem Anforderungsblock. Ein Absatz über „Testabdeckung“ ist möglicherweise bedeutungslos, wenn nicht bekannt ist, dass er zu „Anwendungsfall drei von Service X“ gehört. Daher wird eine zweite Vektor-Einbettung erstellt, um diesen Kontext darzustellen – entweder eine Beschriftung oder eine semantische Zusammenfassung wie „Teil von Anwendungsfall drei von Service X“ –, die die Abruf-Engine bei der Gruppierung verwandter Informationen unterstützt.
Selbst ein einfacher Kontext wie die URL oder die Seitenkennung, aus der der Chunk extrahiert wurde, kann eine wertvolle semantische Verankerung bieten. Dies ist entscheidend, wenn man die Navigation eines Menschen in einer Wissensdatenbank nachahmt: Wir überlegen zunächst, welche Seiten oder Dokumente wahrscheinlich die Antwort enthalten, gehen zu diesen Seiten und suchen dann nach den spezifischen Informationen. Durch die Einbettung dieser Metadaten auf Seiten- oder Abschnittsebene in den zweiten Vektor ermöglichen wir es dem System, zunächst die relevanten Seiten auf der Grundlage des übergeordneten Kontexts abzurufen und dann diese Seiten zu durchsuchen, um präzise Antworten zu extrahieren. Dadurch bleibt die Top-Down-Kohärenz der Informationen erhalten und es wird verhindert, dass Kontext verloren geht, wie es typischerweise der Fall ist, wenn Fragmente aus nicht zusammenhängenden Bereichen vermischt werden.
Theoretisch ist es zwar möglich, die Dokumentstruktur explizit an das LLM zu übergeben oder die Tool-Aufrufschnittstelle zu verwenden, um Dokumente oder Abschnitte anhand von Metadaten zu filtern, doch diese Methode versagt bei großen Dokumentenkorpora. Das Einfügen von Struktur in die Eingabeaufforderung beansprucht Kontextplatz – insbesondere bei kleinen Modellen – und macht das System anfällig und schwer skalierbar. Die vektorbasierte Kontextfilterung ist hingegen dynamisch, skalierbar und für modulare und umfangreiche Abrufaufgaben wesentlich besser geeignet.
Ähnlich verhält es sich mit Code, bei dem die strukturelle Hierarchie erhalten bleiben muss. Eine Methode wie „join()“ enthält möglicherweise keinen textuellen Hinweis darauf, dass sie zur „Klasse A“ gehört, sodass eine Übereinstimmung mit einer Abfrage wie „Wie wird Klasse A implementiert?“ unmöglich ist, sofern kein zusätzlicher Kontext kodiert ist. Das System bettet einen zweiten Vektor ein, der strukturelle Metadaten enthält – z. B. Dateipfad, Klasse oder Modul –, sodass die Suche nicht nur anhand des semantischen Inhalts, sondern auch anhand der strukturellen Position des Codes durchgeführt werden kann.
Diese Strategie ermöglicht eine erste grobe Suche auf der Grundlage eines übergeordneten Kontexts (z. B. Klassennamen, Abschnittsbezeichnungen, Dateipfade), gefolgt von einer feineren Suche auf Inhaltsebene. Auf diese Weise findet das System relevante Gruppen von Chunks, bewahrt die Kohärenz von Dokumenten und Code und reduziert die Kontextfragmentierung erheblich. Außerdem lässt es sich besser skalieren, da größere Chunks mit beibehaltener Struktur indiziert werden können, wodurch die Anzahl der Chunks reduziert wird, ohne dass dabei an wichtigen Stellen an Granularität eingebüßt wird.
Um Halluzinationen zu reduzieren, werden redundante Chunks dedupliziert, um zu vermeiden, dass mehrere identische oder nahezu identische Einträge die endgültige Antwort beeinflussen. Die Chunks werden dann logisch nach ihrer ursprünglichen Reihenfolge oder ihrer Position innerhalb des Dokuments sortiert – dies ist besonders wichtig für prozedurale oder hierarchische Inhalte, bei denen die Reihenfolge eine Rolle spielt. Beispielsweise möchten wir nicht, dass ein Chunk aus der Mitte von Anwendungsfall 3 vor dem Chunk erscheint, der Anwendungsfall 2 einführt. Die logische Sortierung stellt sicher, dass das LLM den Kontext in einer kohärenten, menschenähnlichen Reihenfolge erhält.
Darüber hinaus wird eine dynamische Filterung mithilfe eines sekundären LLM-Aufrufs durchgeführt. Dieses LLM fungiert als Validierungsschicht und prüft, ob jeder abgerufene Chunk semantisch relevant für die Anfrage des Benutzers ist. Anstatt sich ausschließlich auf einen statischen Ähnlichkeitsschwellenwert zu verlassen, der je nach Inhaltstyp stark variieren kann, kann dieses LLM die Anfrage und den Chunk-Inhalt analysieren, um zu entscheiden, ob er weitergeleitet werden soll.
Zusammen simulieren diese Schritte, wie ein menschlicher Analyst eine Suche durchführen würde: Zuerst werden Duplikate entfernt, dann wird der Inhalt logisch strukturiert und schließlich wird bewertet, ob jedes Element tatsächlich zur Beantwortung der Frage beiträgt. Diese mehrschichtige Filterung reduziert die Menge irrelevanter Inhalte, die die finale Generierungsphase erreichen, erheblich, wodurch Halluzinationen minimiert und die Genauigkeit der Antworten erhöht werden. Bei der Arbeit mit einem großen Modell ist dies möglicherweise nicht erforderlich, da das Risiko von Halluzinationen geringer ist.
Der primäre Leistungsengpass war die Anzahl der LLM-Aufrufe und die Kosten für die Tokengenerierung, insbesondere die Zeit, die für die Erstellung der Ausgabetoken benötigt wurde. Empirische Tests bestätigten, dass große Eingabeaufforderungen zwar einen gewissen Einfluss hatten, die Anzahl der Ausgabetoken jedoch einen wesentlich größeren Einfluss auf die Latenz hatte – bis zu dreimal langsamere Antwortzeiten bei längeren Ausgaben. Um dies zu beheben, wurden mehrere gezielte Optimierungen vorgenommen.
Zunächst wurde der Schritt der Umschreibung mehrerer Abfragen, der ursprünglich durch einen dedizierten LLM-Aufruf durchgeführt wurde, an den Dokumentenagenten selbst delegiert. Dadurch wurde ein kompletter Roundtrip entfallen, da der Agent nun mehrere Varianten der Abfrage intern generieren kann, sobald sie benötigt werden. Um die Ausgabelast v en weiter zu reduzieren, haben wir das Format des filternden LLM-Schritts so geändert, dass nur noch eine strukturierte Liste von Chunk-Indizes (z. B. \[0, 3, 6]) zurückgegeben wird, anstatt vollständige Texte neu zu generieren oder zu kopieren. Dadurch wurde die Anzahl der Ausgabetoken massiv reduziert.
Eine weitere wichtige Optimierung war die Behandlung von Referenzen. Anstatt das LLM aufzufordern, vollständige URLs zu generieren oder Dokumente zu zitieren, was Token-Kosten verursacht und Halluzinationen riskiert, fügte das System nach der Antwort programmgesteuert Referenzen anhand der Metadaten aus den abgerufenen Chunks hinzu. Dadurch wurde die Generierung entlastet und gleichzeitig die sachliche Genauigkeit erhöht.
Zusammen führten diese Änderungen nicht nur zu einer geringeren LLM-Nutzung, sondern auch zu einer drastischen Senkung der Token-Generierungskosten und der Latenz. Insgesamt konnte die durchschnittliche Antwortzeit von über einer Minute auf unter 10 Sekunden gesenkt werden – selbst bei Verwendung von Modellen im 14B-Maßstab. Dies zeigt, dass eine intelligente Orchestrierung und ein gutes Prompt-Design wichtiger sind als die reine Rechenleistung.
Durch die systematische Bewältigung dieser Herausforderungen mittels strukturierten Chunkings, kontextbezogener Einbettungen, agentische Orchestrierung der Agent und optimierter LLM-Aufrufe kann ein robusteres, effizienteres und zuverlässigeres RAG-System für den praktischen Einsatz entwickelt werden.









