Initially, the system ingests data from Confluence pages, PDFs, presentations, Excel sheets, and code repositories. Each source requires dedicated adapters for parsing and content extraction.
Text from Confluence pages presents minimal challenges due to its simplicity and ease of ingestion.
Custom-made diagrams in presentations pose significant interpretation challenges, as they are often non-standard and tailored for specific contexts, requiring advanced visual understanding. These diagrams also frequently contain company-specific abbreviations and information, further complicating interpretation. Fully understanding them typically depends on other parts of the document, introducing dependencies that make accurate and comprehensive interpretation even more difficult.
To process the visual information embedded in documents, three major approaches were evaluated:
1. OCR-Based Extraction: Optical Character Recognition (OCR) models can extract visible text from images. While this method is lightweight and fast, it often fails to capture the underlying structure, semantics, and relationships embedded in diagrams. OCR lacks awareness of spatial hierarchies and component-level interpretations in custom illustrations, making it insufficient for deeper semantic tasks.
2. Visual LLMs (VLMs): Visual Large Language Models attempt to process and convert visual content into detailed textual descriptions. This can be approached in two ways:
3. Multimodal Embedding: This method embeds the entire image directly into a vector space without textual translation. While this preserves visual integrity, it struggles with specificity and retrieval precision. A single slide or diagram often contains a dense amount of information—equivalent to several minutes of explanation or an entire page of text. Embedding such a slide as a single unit makes it difficult to later extract or match specific entities—like a person’s name or a service label—especially when these are only visually encoded. As a result, the retrieval stage fails to semantically align user queries with the relevant fragment of the image.
Among these, the most effective approach was using Visual LLMs to generate a structured textual representation of image content. This method allows for the extraction of entities, relationships, and layout semantics in a way that preserves interpretability and avoids dependency on brittle image-only similarity retrieval.
Chunking text into manageable units posed another technical challenge. The chosen strategy is recursive chunking, leveraging headers and subheadings to preserve coherence. An optimal chunk size was found to be around 1,000 tokens with a 200-token overlap. Each chunk includes metadata such as document source URLs and contextual information.
To maintain a fully private, locally hosted system, document embeddings utilize NOMIC models with a 768-dimensional vector size, while code embeddings use Jinja models, also with a 768-dimensional vector size.
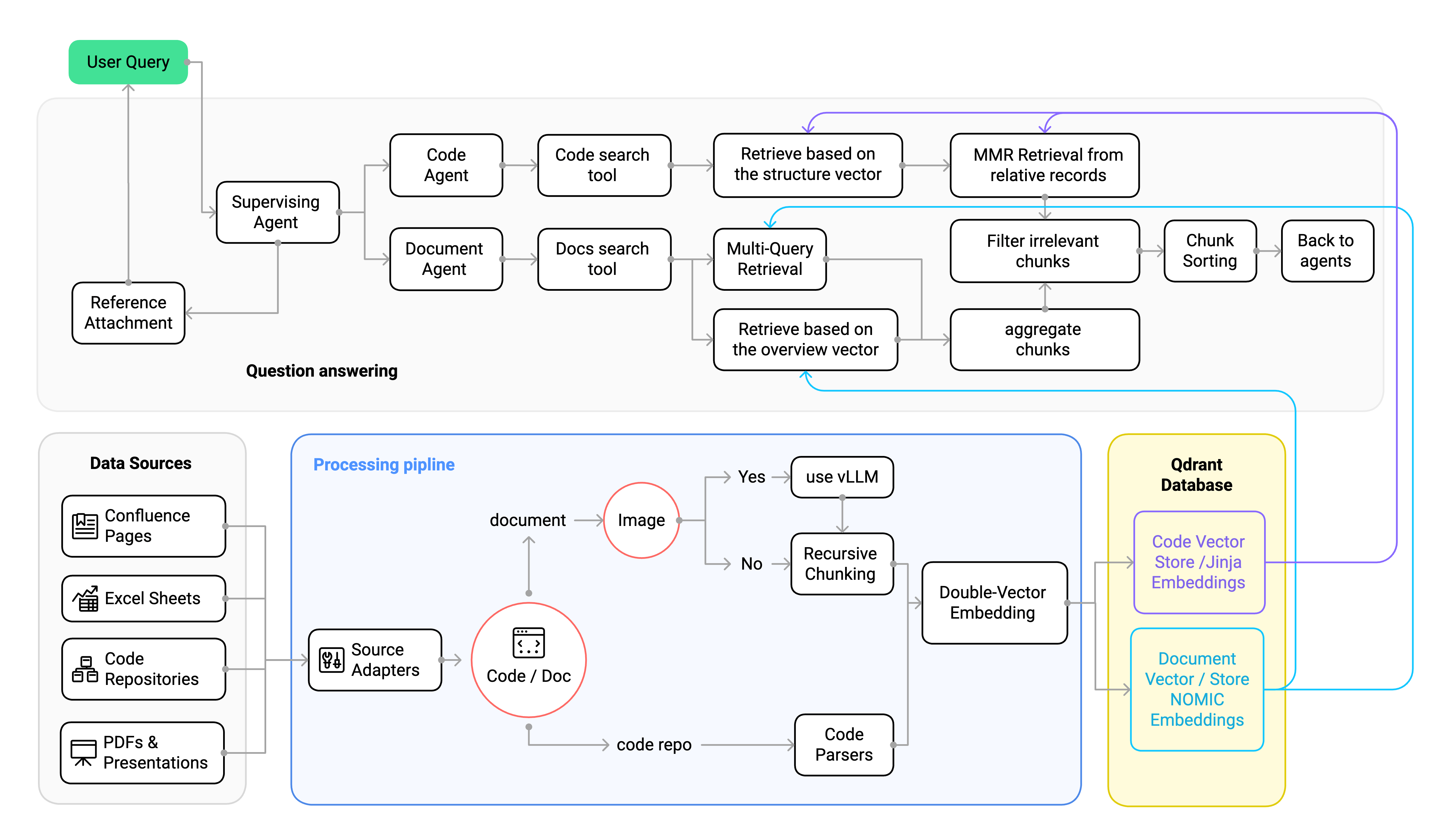
The following diagram illustrates the overall architecture of the RAG system, showing how different components interact to process queries and retrieve information:
1```mermaid
2flowchart LR
3 subgraph subGraph0["Data Sources"]
4 O["Confluence Pages"]
5 P["P
6DFs & Presentations"]
7 Q["Excel Sheets"]
8 R["Code Repositories"]
9 end
10 subgraph subGraph1["Processing Pipeline"]
11 S["Source Adapters"]
12 U["Recursive Chunking"]
13 V["Double-Vector Embedding"]
14 n3["Code / Doc"]
15 n4["Code parsers"]
16 n5["Image"]
17 n6["use vLLM"]
18 end
19 subgraph subGraph2["Question Answering"]
20 K["Chunk Sorting"]
21 M["Reference Attachment"]
22 D["Document Agent"]
23 E["Code Agent"]
24 B["Supervising Agent"]
25 n1["Docs search tool"]
26 n2["Code search tool"]
27 I["Multi-Query Retrieval"]
28 J["MMR Retrieval from relative records"]
29 n7["Retrieve based on the structure vector"]
30 n8["Retrieve based on the overview vector"]
31 n9["Filtering irrelevant chunks"]
32 n10["aggregate chunks"]
33 n11["Back to agents"]
34 end
35 subgraph Databse["Qdrant Database"]
36 G["Document Vector Store<br>NOMIC Embeddings"]
37 H["Code Vector Store<br>Jinja Embeddings"]
38 end
39 A["User Query"] --> B
40 B --> D & E & M
41 D --> n1
42 E --> n2
43 O --> S
44 Q --> S
45 R --> S
46 S --> n3
47 U --> V
48 V --> G & H
49 n1 --> I & n8
50 M --> A
51 n2 --> n7
52 I --> n10
53 J --> n9
54 n3 -- code repo --> n4
55 n3 -- document --> n5
56 n4 --> V
57 P --> S
58 n5 -- Yes --> n6
59 n6 --> U
60 n5 -- No --> U
61 n7 --> J
62 n8 --> n10
63 n9 --> K
64 H --> J & n7
65 G --> n8 & I
66 n10 --> n9
67 K --> n11
68 n3@{ shape: decision}
69 n5@{ shape: diam}
70 style G stroke:#2962FF
71 style H stroke:#AA00FF
72 style A fill:#00C853
73 style subGraph1 fill:#BBDEFB
74 style Databse fill:#FFF9C4
75 linkStyle 29 stroke:#AA00FF,fill:none
76 linkStyle 30 stroke:#AA00FF,fill:none
77 linkStyle 31 stroke:#2962FF,fill:none
78 linkStyle 32 stroke:#2962FF,fill:none
Document chunking is simplified by converting text to markdown format, using a recursive approach based on markdown elements to maintain contextual coherence. Conversely, code chunking presents unique challenges due to structural elements like functions and classes potentially being split. A solution implemented is the use of tree splitters, which parse the code structure to ensure chunk integrity. Documents and code are stored in separate databases to distinctly manage metadata. This separation is essential because different embedding models are used for each modality—document embeddings focus on textual semantics, while code embeddings are optimized for structural and syntactic representation. Keeping them isolated allows the retrieval process to remain clean and targeted, preventing context contamination across domains. It also makes retrieval more efficient and scalable, enabling the system to maintain individual databases per project or repository. This architecture allows for selective querying across specific repositories or document groups without loading irrelevant data, which becomes increasingly important as the system scales.
Retrieval involves processing user queries through agents orchestrated by a supervising agent. The decision to adopt an agentic approach stems from the need to handle complexity and modularize functionality in a scalable way. Instead of overloading a single LLM with all retrieval and synthesis tasks, responsibilities are delegated across specialized agents.
Specifically, two retrieval agents are used: one dedicated to handling document queries and another for code-related queries. Each agent is optimized for its domain—leveraging distinct embedding models, querying separate vector stores, and interpreting domain-specific semantics appropriately. This separation prevents cross-contamination of results, reduces hallucination risks, and enables clearer traceability of outputs. Additionally, the code agent can make use of specialized LLMs trained for programming tasks—such as coder-focused models—which have a much deeper understanding of code semantics, syntax, and patterns. This enhances both the relevance and quality of responses for code-related questions, making the overall system more robust and contextually accurate in software engineering scenarios.
Moreover, this architecture allows for easy extensibility: individual projects or codebases can have their own retrieval agent or associated database, which can be dynamically selected or queried when needed. This modularity ensures that the system remains maintainable and scalable as the scope and complexity of the knowledge base grows.
For code retrieval, Maximal Marginal Relevance (MMR) is utilized to ensure diverse results. The document retrieval process leverages a multi-query approach to enhance relevance.
With all components in place—including modular adapters, chunking, and an agentic retrieval architecture—the system is now positioned to answer a wide range of questions. However, it is equally important to recognize the boundaries of what can and cannot be reliably answered. The following sections explore the types of questions that the system can handle, the conditions that must be met for those answers to be accurate, and the fundamental challenges that persist despite this structured design.
Document-related questions encompass various scenarios:
Code-related questions similarly cover a range of complexities:
Enhanced embedding strategies introduce double-vector embeddings, combining content and contextual metadata. This is critical because relying only on the chunk content often fails to preserve the document or code structure needed for accurate retrieval.
For documents, the context of a chunk is often defined not just by the paragraph itself but by its location in a larger section—like a use case, service description, or requirements block. A paragraph about "test coverage" might be meaningless without knowing it belongs to "use case three of Service X". Therefore, a second vector embedding is created to represent this context—either a label or semantic summary, like "part of use case three of Service X"—which guides the retrieval engine in grouping related information.
Even a simple context such as the URL or page identifier from which the chunk was extracted can provide valuable semantic anchoring. This becomes crucial when emulating how a human would navigate a knowledge base: we first think about which pages or documents are likely to contain the answer, go to those pages, and then look for the specific information. By embedding this page-level or section-level metadata into the second vector, we enable the system to first retrieve the relevant pages based on the high-level context and then drill down into those pages to extract precise answers. This preserves the top-down coherence of the information and prevents the loss of context that typically arises when chunks from unrelated areas are mixed.
While it is theoretically possible to pass the document structure explicitly to the LLM or to use the tool call interface to filter documents or sections based on metadata, this method breaks down when the document corpus is large. Injecting structure into the prompt consumes context space—especially with small models—and makes the system brittle and harder to scale. Instead, this vector-based contextual filtering is dynamic, scalable, and much better suited for modular and large-scale retrieval tasks.
Similarly, for code, the structural hierarchy must be preserved. A method like `join()` may not contain any textual indication that it belongs to `class A`, making it impossible to match to a query like "How is class A implemented?" unless additional context is encoded. The system embeds a second vector that includes structural metadata—e.g., file path, class, or module—allowing retrieval to be performed not just on semantic content but also based on the code's structural location.
This strategy allows for an initial coarse retrieval based on high-level context (e.g., class names, section labels, file paths), followed by finer content-level similarity. As a result, the system retrieves relevant groups of chunks together, maintains document and code coherence, and dramatically reduces context fragmentation. It also scales better, since larger chunks can be indexed with retained structure, reducing chunk counts without sacrificing granularity where it matters.
To reduce hallucinations, redundant chunks are deduplicated to avoid multiple identical or near-identical entries from affecting the final answer. Chunks are then logically sorted based on their original order or their position within the document—this is crucial especially for procedural or hierarchical content where sequence matters. For instance, we don't want a chunk from the middle of Use Case 3 appearing before the chunk that introduces Use Case 2. Logical sorting ensures the LLM receives context in a coherent, human-like order.
Beyond that, dynamic filtering is applied using a secondary LLM call. This LLM acts as a validation layer, checking whether each retrieved chunk is semantically relevant to the user's query. Instead of relying solely on a static similarity threshold—which can vary wildly across content types—this LLM can reason over the query and chunk content to decide if it should be passed forward.
Together, these steps simulate how a human analyst would approach a search: first remove duplicates, then structure the content logically, and finally, evaluate whether each piece actually helps answer the question. This layered filtration significantly reduces irrelevant content reaching the final generation phase, thereby minimizing hallucinations and boosting the precision of responses. This may be not needed when working with a big model because there is less risk of hallucination.
The primary performance bottleneck identified was the number of LLM calls and the cost of token generation, especially the time taken to produce output tokens. Empirical testing confirmed that while large input prompts had some impact, the number of output tokens had a substantially greater influence on latency—up to 3× slower response times for longer outputs. To address this, several targeted optimizations were applied.
First, the multi-query rewriting step—originally done by a dedicated LLM call—was delegated to the document agent itself. This removed an entire round-trip by allowing the agent to generate multiple variations of the query internally at the moment it needed them. Then, to reduce the output burden further, we changed the format of the filtering LLM step to return only a structured list of chunk indices (e.g., \[0, 3, 6]) instead of regenerating or copying full texts. This massively reduced output token count.
Another key optimization was handling references. Instead of asking the LLM to generate full URLs or cite documents, which incurs token cost and risks hallucinations, the system programmatically attached references post-response using metadata from the retrieved chunks. This removed pressure on generation while also increasing factual accuracy.
Together, these changes not only reduced LLM usage but also drastically lowered token generation cost and latency. In aggregate, this brought total response time from over a minute to under 10 seconds on average—even when using models like 14B scale, demonstrating that smart orchestration and prompt design are more critical than raw compute size alone.
By systematically addressing these challenges through structured chunking, contextual embeddings, agentic orchestration, and optimized LLM calls, a more robust, efficient, and reliable real-world RAG system can be developed.










